Building a RTMP Video Streamer with NGINX Part 2 - Caching with NGINX

Building my own cache
In the previous post, I discussed how to compile NGINX with the RTMP module to enable your webcam or a static file (using FFMPEG) to stream RTMP content.
Now, let’s explore a scenario where you can enhance the stream’s reach and reduce latency by deploying small NGINX instances across a network. These instances would cache the content and serve it to clients closest to the cache. But first, let’s create a sandbox for testing this approach.
The Topology
Before we start my little experiment lets review the topology that I have put together. I have a bit of a service provider background, so I am taking some cues from that world to develop a small topology that is slightly resembling of a typical service provider network design. 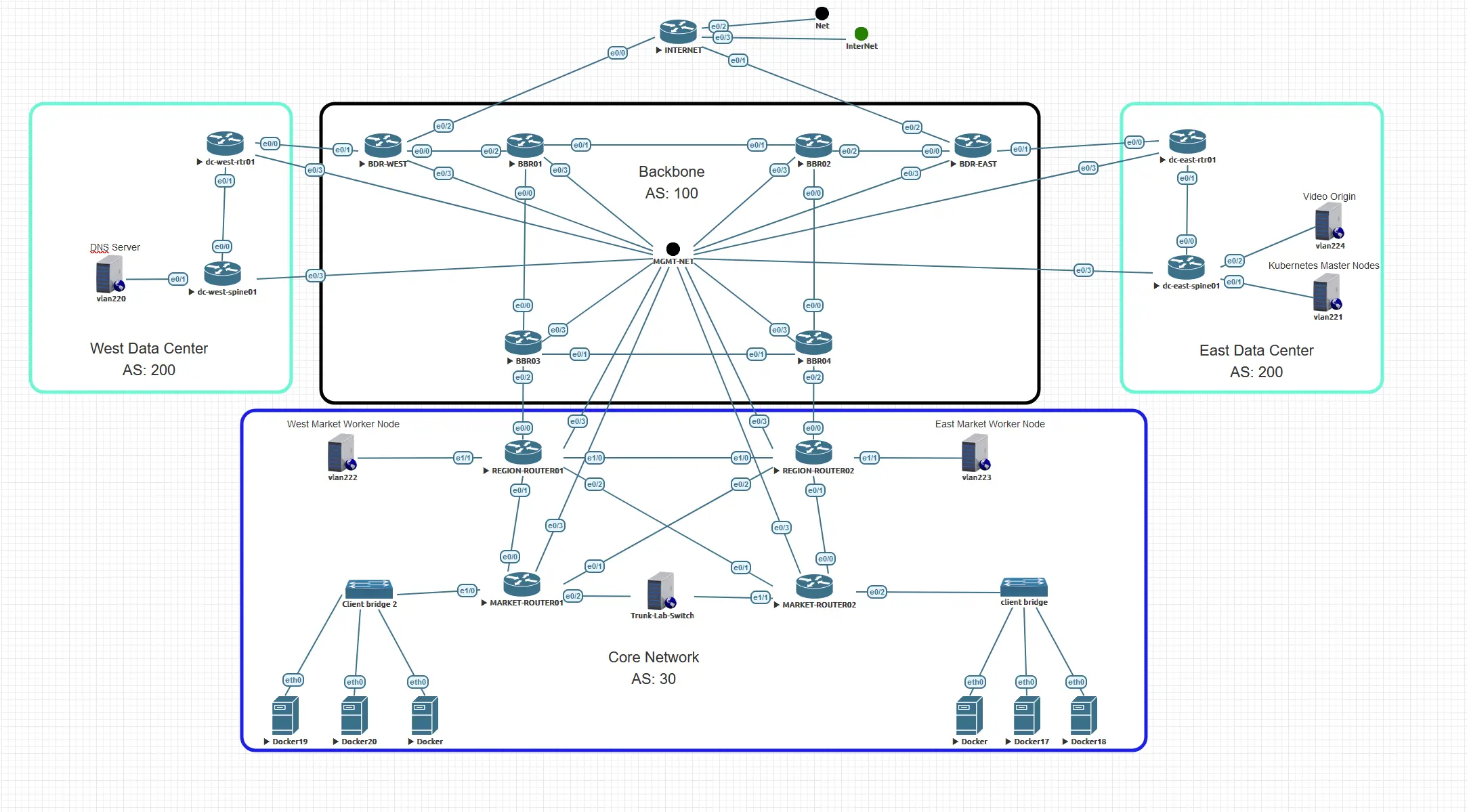
In this diagram we have a couple of components.
- The Backbone Network
- BGP Autonomous System Number (ASN) 100 and OSPF Area 0.
- BGP will be configured in a full mesh. This means that every Backbone router(BBR) will peer with all other routers in ASN 100.
- The Backbone Datacenter Routers (BDR) and BBR03 and BBR04 will act as edges for ASN 100 connected to the Data Center and Region respectively.
- The Core Network
- BGP Autonomous System Number (ASN) 30 and OSPF Area 0.
- BGP will be configured in a full mesh.
- Worker nodes are placed in this network to be closest to the clients. Clients are Docker containers running linux with VLC.
- Data Center Network
- BGP Autonomous System Number (ASN) 200 and OSPF Area 0.
- iBGP between the RTR and Spine, RTRs peers with ASN 100
- DNS is hosted on the West DC while the Kubernetes master nodes are hosted only in the East DC.
- The origin video stream will be hosted in the East DC as well.
If a client wanted to connect to the video stream at the origin in the East DC it would have to traverse the network from ASN 30 through ASN 100 and into ASN 200 at the East DC and then back again. It large networks this could include a lot of hops, a lot of latency for the round trip and potentially a lot of bandwidth that would have to be built out between the client network and the DC network to handle daily peaks or even large event peaks that might happen once a year. 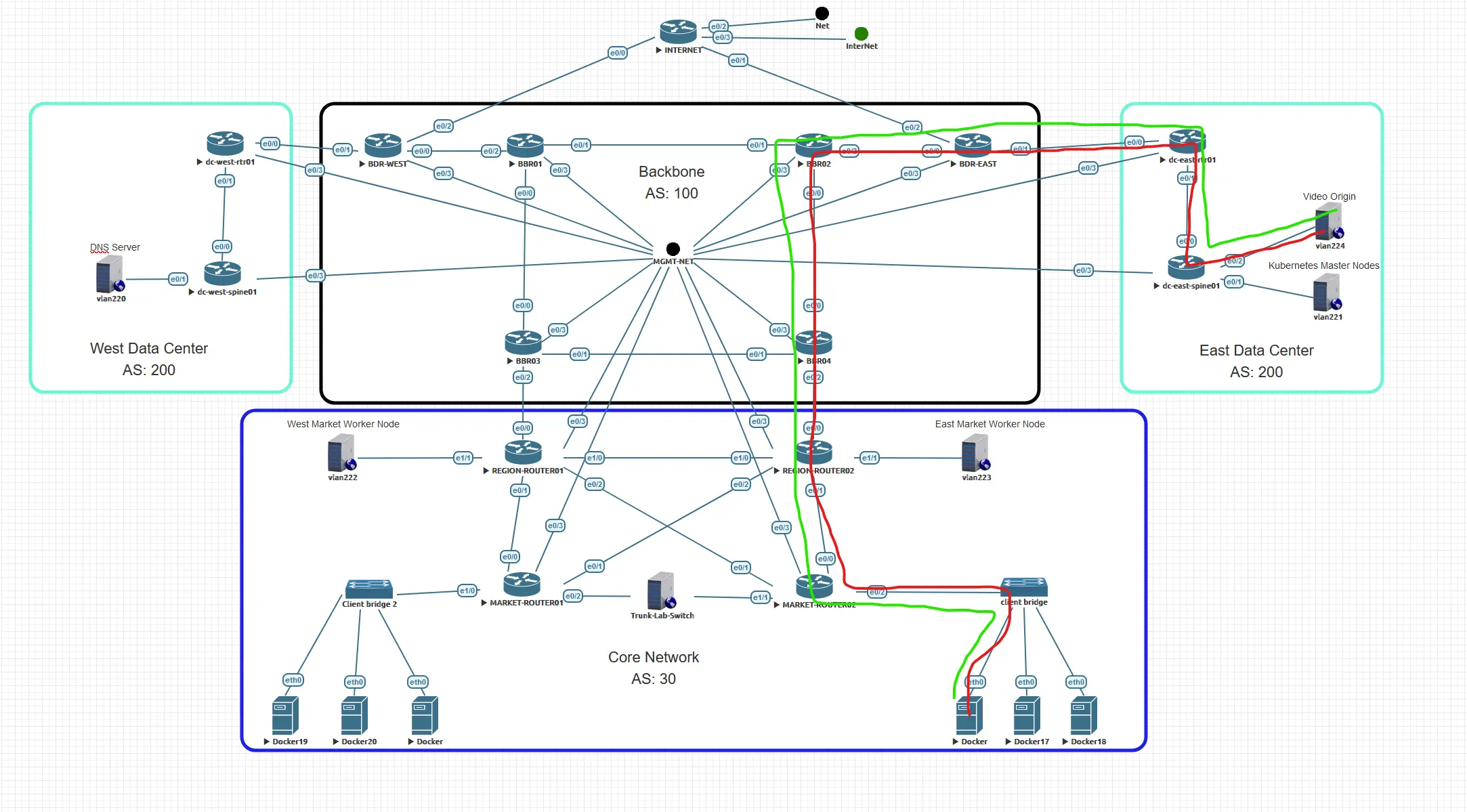
To deal with this we need to place the source closer to the client, that way we can avoid building large amounts of capacity between the client the origin, and we get better performance for the client because the source for the client is closer.
Using Ansible to deploy K3S
Lets assume that there are cloud providers connected in somewhat close proximity to clients who want to consume your content. We could for the period of time of the live stream deploy an NGINX container into this network for the duration of the broadcast. In my example I am going to use Ubuntu VMs as worker nodes as part of my K3S cluster. My Master nodes will reside in my East DC which will be used to control the worker nodes and deploy NGINX out to those worker nodes.
In our pretend scenario the cloud provider is using Proxmox to host their VMs. That is good news because so are we. In this playbook we use the proxmox API to deploy a set of 3 master nodes in our Datacenter and another set of worker nodes in the clouds providers East and West connectivity to the Core network.
Our Ansible inventory will look something like this, notice that because of the topology we won’t be able to have our worker nodes and masters nodes in the same subnet.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
all:
children:
k3s_cluster:
children:
master:
hosts:
lab-k3s01:
ansible_host: 172.16.221.38
ansible_username: ansibleuser
vmid: 3001
storage: "ssd02-4T"
vcpus: 4
memory: 4096
data_vlan: 221
label: master
lab-k3s02:
ansible_host: 172.16.221.39
ansible_username: ansibleuser
vmid: 3002
storage: "ssd02-4T"
vcpus: 4
memory: 4096
data_vlan: 221
label: master
lab-k3s03:
ansible_host: 172.16.221.40
ansible_username: ansibleuser
vmid: 3003
storage: "ssd02-4T"
vcpus: 4
memory: 4096
data_vlan: 221
label: master
node:
hosts:
west-lab-k3s01:
ansible_host: 172.16.222.41
ansible_username: ansibleuser
vmid: 3004
storage: "ssd02-4T"
vcpus: 4
memory: 4096
data_vlan: 222
label: west-worker
east-lab-k3s01:
ansible_host: 172.16.223.42
ansible_username: ansibleuser
vmid: 3005
storage: "ssd02-4T"
vcpus: 4
memory: 4096
data_vlan: 223
label: east-worker
Because of the difference in subnets we will need to use Cilium as our Container Network Interface (CNI), Cilium allows us to not only use tunneling to connect all of the Master and Work nodes, but we can also provide specific BGP configurations for each node based on its label. Cilium also provides an Ingress controller component as well which we will use as well.
The playbook I will use to deploy the entire cluster will look something like this, I will go into a little more detail on the components of this playbook in a later post.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
---
- name: Prepare Proxmox VM Cluster
hosts: localhost
gather_facts: true
vars_files:
- vault.yml
vars_prompt:
- name: node
prompt: What Prox node do you want to deploy on?
private: false
- name: template_id
prompt: What Prox template do you want to use (Prox Template VMID)?
private: false
roles:
- role: deploy_proxmox_vm
when: prox_api is defined
- name: Create and Mount NFS share to VMs
hosts: k3s_cluster
gather_facts: true
vars_files:
- vault.yml
tasks:
- name: Install qemu-guest-agent, nfs-common, and open-iscsi
ansible.builtin.apt:
name:
- qemu-guest-agent
- nfs-common
- open-iscsi
state: present
update_cache: true
become: true
- name: Reboot the node
ansible.builtin.reboot:
become: true
when: ansible_facts['distribution'] == 'Ubuntu'
- block:
- name: Enable and start open-iscsi
ansible.builtin.systemd:
name: open-iscsi
state: started
enabled: yes
become: true
- block:
- name: Ensure mount directory exists
ansible.builtin.file:
path: /mnt/longhorn/data
state: directory
become: true
- name: Ensure NFS share is mounted
ansible.posix.mount:
path: /mnt/longhorn/data
src: "{{ nfs_mount }}"
fstype: nfs
opts: defaults
state: mounted
become: true
when: nfs_mount is defined
- block:
- name: Discover iscsi targets
command: iscsiadm -m discovery -t st -p {{ iscsi_host }}
become: true
- name: Login to iscsi target
command: iscsiadm -m node --targetname {{ hostvars[inventory_hostname]['iscsi_target'] }} --portal {{ iscsi_host }}:3260 --login
become: true
- name: Format the disk
ansible.builtin.filesystem:
fstype: ext4
dev: /dev/sdb
become: true
- name: Create directory
file:
path: /mnt/iscsi
state: directory
mode: '0755'
become: true
- name: Mount the disk
mount:
path: /mnt/iscsi
src: /dev/sdb
fstype: ext4
state: mounted
opts: _netdev
become: true
- name: Add mount to fstab
lineinfile:
path: /etc/fstab
line: '/dev/sdb /mnt/iscsi ext4 _netdev 0 0'
state: present
become: true
when: hostvars[inventory_hostname]['iscsi_target'] is defined
- name: Pre tasks
hosts: k3s_cluster
pre_tasks:
- name: Verify Ansible is version 2.11 or above. (If this fails you may need to update Ansible)
assert:
that: "ansible_version.full is version_compare('2.11', '>=')"
msg: >
"Ansible is out of date."
- name: Prepare k3s nodes
hosts: k3s_cluster
gather_facts: true
environment: "{{ proxy_env | default({}) }}"
roles:
- role: prereq
become: true
- role: download
become: true
- role: k3s_custom_registries
become: true
when: custom_registries
- name: Setup k3s servers
hosts: master
environment: "{{ proxy_env | default({}) }}"
roles:
- role: k3s_server
become: true
- name: Setup k3s agents
hosts: node
environment: "{{ proxy_env | default({}) }}"
roles:
- role: k3s_agent
become: true
- name: Configure k3s cluster
hosts: master
environment: "{{ proxy_env | default({}) }}"
roles:
- role: k3s_server_post
become: true
- name: Copy kueconfig into .kubeconfig/config
hosts: localhost
environment: "{{ proxy_env | default({}) }}"
tasks:
- name: Create .kube directory
ansible.builtin.file:
path: "{{ ansible_user_dir }}/.kube"
state: directory
- name: Copy kubeconfig into .kube/config
ansible.builtin.copy:
src: ./kubeconfig
dest: "{{ home_dir }}/.kube/config"
mode: '0600'
As part of the k3s_server_post role I have included a template that configures the Cilium BGP peers based on the node role provided in the playbook.
- In this configuration below I setup the neighbors with each router that our master, and worker nodes are directly connected to.
- At the bottom I have configured the subnet that will be advertised from the worker nodes when NGINX is deployed.
- This range will be used by the Cilium Load Balancer and will chose the next available IP in the range as Ingress configurations are added.
- We will take that IP address and configure the DNS server with an A record pointing an FQDN to the address advertised.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: 01-bgp-master-peering-policy
spec:
virtualRouters:
- localASN: {{ cilium_bgp_asn }}
exportPodCIDR: {{ cilium_exportPodCIDR | default('true') }}
neighbors:
- peerAddress: '{{ cilium_master_bgp_peer_address + "/32"}}'
peerASN: {{ cilium_master_bgp_peer_asn }}
eBGPMultihopTTL: 10
connectRetryTimeSeconds: 120
holdTimeSeconds: 90
keepAliveTimeSeconds: 30
gracefulRestart:
enabled: true
restartTimeSeconds: 120
nodeSelector:
matchLabels:
master: master
---
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: 01-bgp-west-worker-peering-policy
spec:
virtualRouters:
- localASN: {{ cilium_bgp_asn }}
exportPodCIDR: {{ cilium_exportPodCIDR | default('true') }}
podIPPoolSelector:
matchExpressions:
- {key: somekey, operator: NotIn, values: ['never-used-value']}
serviceSelector:
matchExpressions:
- {key: somekey, operator: NotIn, values: ['never-used-value']}
neighbors:
- peerAddress: '{{ cilium_west_bgp_peer_address + "/32"}}'
peerASN: {{ cilium_west_bgp_peer_asn }}
eBGPMultihopTTL: 10
connectRetryTimeSeconds: 120
holdTimeSeconds: 90
keepAliveTimeSeconds: 30
gracefulRestart:
enabled: true
restartTimeSeconds: 120
nodeSelector:
matchLabels:
worker: west-worker
---
apiVersion: "cilium.io/v2alpha1"
kind: CiliumBGPPeeringPolicy
metadata:
name: 01-bgp-east-worker-peering-policy
spec:
virtualRouters:
- localASN: {{ cilium_bgp_asn }}
exportPodCIDR: {{ cilium_exportPodCIDR | default('true') }}
podIPPoolSelector:
matchExpressions:
- {key: somekey, operator: NotIn, values: ['never-used-value']}
serviceSelector:
matchExpressions:
- {key: somekey, operator: NotIn, values: ['never-used-value']}
neighbors:
- peerAddress: '{{ cilium_east_bgp_peer_address + "/32"}}'
peerASN: {{ cilium_east_bgp_peer_asn }}
eBGPMultihopTTL: 10
connectRetryTimeSeconds: 120
holdTimeSeconds: 90
keepAliveTimeSeconds: 30
gracefulRestart:
enabled: true
restartTimeSeconds: 120
nodeSelector:
matchLabels:
worker: east-worker
---
apiVersion: "cilium.io/v2alpha1"
kind: CiliumLoadBalancerIPPool
metadata:
name: "01-lb-pool"
spec:
cidrs:
- cidr: "{{ cilium_bgp_lb_cidr }}"
Lets assume now that all nodes have been deployed, Cilium is setup as an Ingress controller for the cluster, now we need to build out our NGINX deployment.
Building the NGINX Custom Container
We need to create a customer container from the Latest NGINX container so that we can place inside of this custom container our customized NGINX configuration file.
Create a Github repo for the container and place these files into it
Dockerfile - This will be used by the docker build command to ensure that our nginx.conf file is placed in the correct folder on the container.
1
2
3
4
5
FROM nginx:latest
COPY nginx.conf /etc/nginx/nginx.conf
EXPOSE 80
Makefile - Allows us to simply use the ‘'’make’’’ command to build, push or pull our container.
1
2
3
4
5
6
7
8
build:
docker build -t ghcr.io/byrn-baker/nginx-cache-docker:v0.0.1 .
push:
docker push ghcr.io/byrn-baker/nginx-cache-docker:v0.0.1
pull:
docker pull ghcr.io/byrn-baker/nginx-cache-docker:v0.0.1
nginx.conf - In this file we configure our nginx container to perform the proxy_cache function
- In the HTTP section of the configuration
- We define where our access log should be stored
- We define where the proxy cache path should be, I am encoding in both HLS and DASH so those will be separate folder locations.
- We are also defining for how long segments should be cached, how large of a file is cached, and how long an inactive segment should stay cached.
- In the Server section we define the listening port as well as the location for where our two formats can be located on this webserver.
- We also define the URL for the origin so that this NGINX server can proxy the connections from the clients to the origin.
- We define how long the requests should be cached as well as provide some headers for the client so we can tell if we are getting a cache hit or miss. Useful for troubleshooting and other stuff.
- the sub filter will ensure that the client requests are correctly rewritten when proxied so that the request makes it up to the origin and back. Not all requests will be cached, because the first client to request the stream will need to ultimately talk to the origin, this establishes the flow between the origin and this NGINX proxy cache. As more clients connect our caching efficiency increases and latency between the clients requesting the stream and receiving it should go down.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
events {}
http {
access_log /var/log/nginx/access.log;
proxy_cache_path /var/cache/nginx/HLS levels=1:2 keys_zone=HLS:10m max_size=1g inactive=10s use_temp_path=off;
proxy_cache_path /var/cache/nginx/DASH levels=1:2 keys_zone=DASH:10m max_size=1g inactive=10s use_temp_path=off;
proxy_cache_key "$scheme$request_method$host$request_uri";
server {
listen 80;
location /hls/ {
proxy_cache HLS;
proxy_pass http://origin.example.com:80/hls/;
proxy_set_header Host $host;
proxy_buffering on;
proxy_cache_valid 200 10s; # Cache HLS responses for 10 seconds
proxy_cache_valid 404 1m;
add_header X-Proxy-Cache $upstream_cache_status;
add_header X-Cache-Status $upstream_cache_status;
sub_filter 'http://origin.example.com:80/hls/' 'http://$host/hls/';
sub_filter_once off;
}
location /dash/ {
proxy_cache DASH;
proxy_pass http://origin.example.com:80/dash/;
proxy_set_header Host $host;
proxy_buffering on;
proxy_cache_valid 200 10s; # Cache DASH responses for 10 seconds
proxy_cache_valid 404 1m;
add_header X-Proxy-Cache $upstream_cache_status;
add_header X-Cache-Status $upstream_cache_status;
sub_filter 'http://origin.example.com:80/dash/' 'http://$host/dash/';
sub_filter_once off;
}
}
}
Deploying the NGINX Custom Container into Kubernetes
Now that we have our container built lets take a look at how to deploy it. I’ve created a playbook to perform this task as well. We need to create a secret in the namespace on the cluster we intend to deploy nginx, this secret if for the container repository that the customer container has been stored into (if you want a quick lesson on how to automate this further check out this post from technotim).
My playbook looks something like this, I am using vault to store secrets in, you can find more out about that here.
1
2
3
4
5
6
7
8
9
---
# usage ansible-playbook pb.install-nginx-cache.yml --ask-vault-pass --tags="install"
- name: Install Nginx-Cache on k3s
hosts: localhost
vars_files:
- vault.yml
roles:
- role: install_nginx_cache
The install_nginx_cache role looks something like this.
- Creating the docker register secret - this provide the cluster a way to pull down the container from the Github container registry where I have stored my customer container.
- Create a Deployment - The task simply creates a name for this deployment, places it in the default namespace, the annotations tell it to use Cilium for ingress.
- I want to have 3 replicas running at all times.
- Under spec I have defined that this is a container and from where it should be pulled.
- I have also include a mount path for the container, this will be used by the container to store the cache segments from the origin.
- You can build these paths directly to RAM for quicker access if you want as well. This is defined near the bottom by the key value pair of medium.
- We create a service that can be exposed externally or mapped by an ingress
- The ingress rules will route traffic to this container based on the clients host name in the clients request.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
- block:
- name: Create a docker registry secret
community.kubernetes.k8s:
state: present
definition:
apiVersion: v1
kind: Secret
metadata:
name: ghcr-io-creds
namespace: default
type: kubernetes.io/dockerconfigjson
data:
.dockerconfigjson: "{{ docker_config | to_json | b64encode }}"
vars:
docker_config:
auths:
ghcr.io/byrn-baker/nginx-cache-docker:
username: "{{ vault_docker_username }}"
password: "{{ vault_docker_password }}"
auth: "{{ (vault_docker_username + ':' + vault_docker_password) | b64encode }}"
- name: Create a deployment
community.kubernetes.k8s:
definition:
kind: Deployment
apiVersion: apps/v1
metadata:
name: nginx-cache
namespace: default
labels:
app: nginx-cache
annotations:
io.cilium.proxy-visibility: "<Ingress/80/TCP/HTTP>"
spec:
replicas: 3
progressDeadlineSeconds: 600
revisionHistoryLimit: 2
strategy:
type: Recreate
selector:
matchLabels:
app: nginx-cache
template:
metadata:
labels:
app: nginx-cache
spec:
containers:
- name: nginx-cache
image: ghcr.io/example/nginx-cache-docker:v0.0.1
imagePullPolicy: Always
volumeMounts:
- mountPath: /var/cache/nginx
name: cache-volume
imagePullSecrets:
- name: ghcr-io-creds
volumes:
- name: cache-volume
emptyDir:
medium: Memory
state: present
- name: Create a service for nginx-cache
community.kubernetes.k8s:
definition:
kind: Service
apiVersion: v1
metadata:
name: nginx-cache
namespace: default
spec:
selector:
app: nginx-cache
ports:
- protocol: TCP
port: 80
targetPort: 80
state: present
- name: Create a cilium Ingress for NGINX
community.kubernetes.k8s:
definition:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-ingress
namespace: default
spec:
ingressClassName: cilium
rules:
- host: "live.example.com"
http:
paths:
- backend:
service:
name: nginx-cache
port:
number: 80
path: /
pathType: Prefix
state: present
tags: install
Checking connectivity
If all goes well we should see outputs like the below. This tells us that the pods are running, our ingress is configured, and we have a service created for the deployment that has been assigned an external IP that matches our ingress.
1
2
3
4
5
$ k get pods
NAME READY STATUS RESTARTS AGE
nginx-cache-75d55cb78-psk6b 1/1 Running 0 6h3m
nginx-cache-75d55cb78-qsvh8 1/1 Running 0 6h3m
nginx-cache-75d55cb78-xtfg9 1/1 Running 0 6h3m
1
2
3
$ k get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
nginx-ingress cilium live.lab.video-ops-lab.com 172.16.228.2 80 6h59m
1
2
3
4
5
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cilium-ingress-nginx-ingress LoadBalancer 10.43.250.206 172.16.228.2 80:32519/TCP,443:31901/TCP 6h59m
kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 7h52m
nginx-cache ClusterIP 10.43.219.152 <none> 80/TCP 6h59m
While we are checking things lets have a look at some routers output as well. ASN 64513 is the ASN assigned to the Kubernetes cluster.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
region-router01#sh ip bgp sum
BGP router identifier 172.16.30.128, local AS number 30
BGP table version is 23, main routing table version 23
13 network entries using 1820 bytes of memory
20 path entries using 1600 bytes of memory
8/5 BGP path/bestpath attribute entries using 1152 bytes of memory
3 BGP AS-PATH entries using 72 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
BGP using 4644 total bytes of memory
BGP activity 104/75 prefixes, 232/191 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
172.16.30.129 4 30 484 482 23 0 0 07:09:38 8
172.16.30.130 4 30 478 485 23 0 0 07:09:37 1
172.16.30.131 4 30 476 481 23 0 0 07:09:38 3
172.16.100.12 4 100 481 483 23 0 0 07:09:37 4
172.16.222.41 4 64513 863 951 23 0 0 07:09:26 3
1
2
3
4
5
6
7
8
9
10
11
region-router01#sh ip bgp
BGP table version is 23, local router ID is 172.16.30.128
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
* i 172.16.228.3/32 172.16.30.129 0 100 0 64513 i
*> 172.16.222.41 0 64513 i
Notice that we have two next hops for 172.16.228.3/32, that is because both workers are currently advertising the same route, this is good because both workers are also running the NGINX container as well.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
region-router02#sh ip bgp sum
BGP router identifier 172.16.30.129, local AS number 30
BGP table version is 29, main routing table version 29
13 network entries using 1820 bytes of memory
20 path entries using 1600 bytes of memory
8/5 BGP path/bestpath attribute entries using 1152 bytes of memory
3 BGP AS-PATH entries using 72 bytes of memory
0 BGP route-map cache entries using 0 bytes of memory
0 BGP filter-list cache entries using 0 bytes of memory
BGP using 4644 total bytes of memory
BGP activity 79/50 prefixes, 199/158 paths, scan interval 60 secs
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
172.16.30.128 4 30 485 486 29 0 0 07:12:18 8
172.16.30.130 4 30 480 485 29 0 0 07:12:18 1
172.16.30.131 4 30 477 485 29 0 0 07:12:18 3
172.16.100.14 4 100 491 488 29 0 0 07:12:18 4
172.16.223.42 4 64513 869 953 29 0 0 07:12:04 3
1
2
3
4
5
6
7
8
9
10
11
region-router02#sh ip bgp
BGP table version is 29, local router ID is 172.16.30.129
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
* i 172.16.228.2/32 172.16.30.128 0 100 0 64513 i
*> 172.16.223.42 0 64513 i
Lets also just check the BGP table on our market routers as well. Our clients are directly connected to these routers so they will need to be able to communicate with the worker nodes.
1
2
3
4
5
6
7
8
9
10
11
market-router01#sh ip bgp
BGP table version is 113, local router ID is 172.16.30.130
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*>i 172.16.228.2/32 172.16.30.128 0 100 0 64513 i
* i 172.16.30.129 0 100 0 64513 i
1
2
3
4
5
6
7
8
9
10
11
market-router02#sh ip bgp
BGP table version is 24, local router ID is 172.16.30.131
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale, m multipath, b backup-path, f RT-Filter,
x best-external, a additional-path, c RIB-compressed,
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*>i 172.16.228.2/32 172.16.30.128 0 100 0 64513 i
* i 172.16.30.129 0 100 0 64513 i
Lets check a traceroute from Docker18 and then from Docker20. The ingress controller does not respond to pings, so our traceroute looks a little funky, but we seeing the gateway in the traceroute followed by a *. I will take that as at least the path exists to the workers. 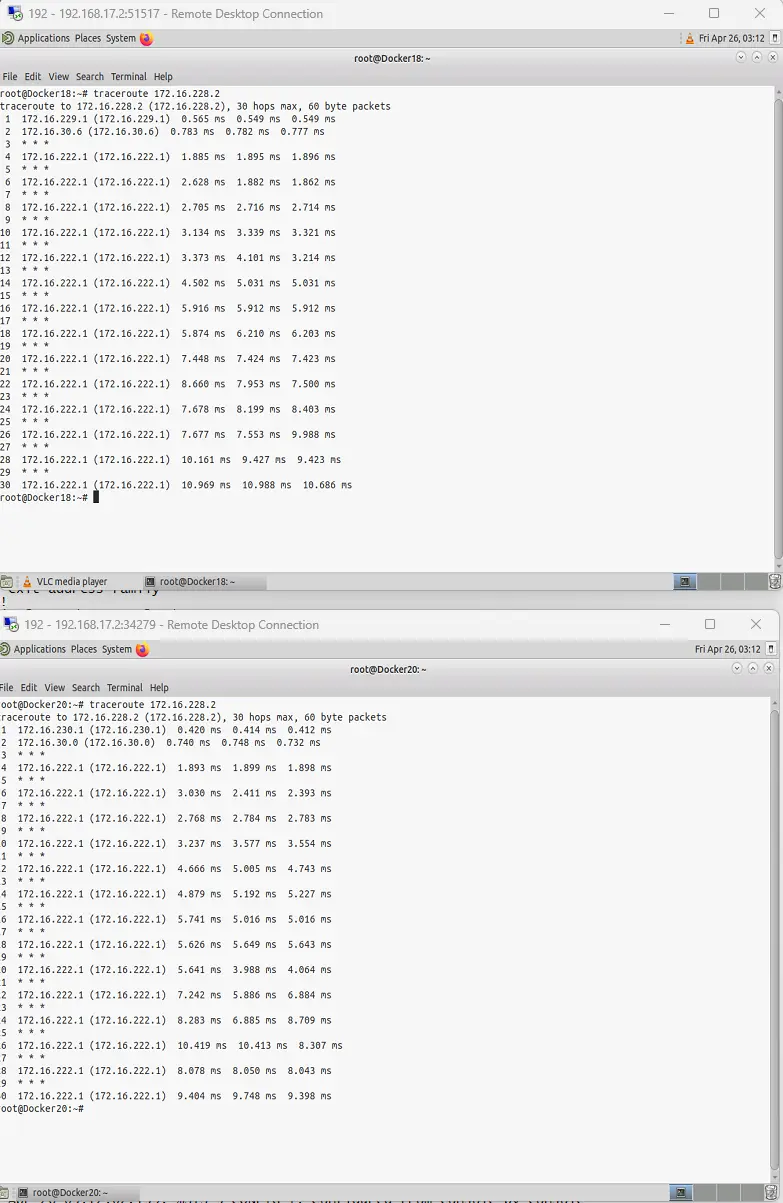
Lets see if we can now load the stream in VLC 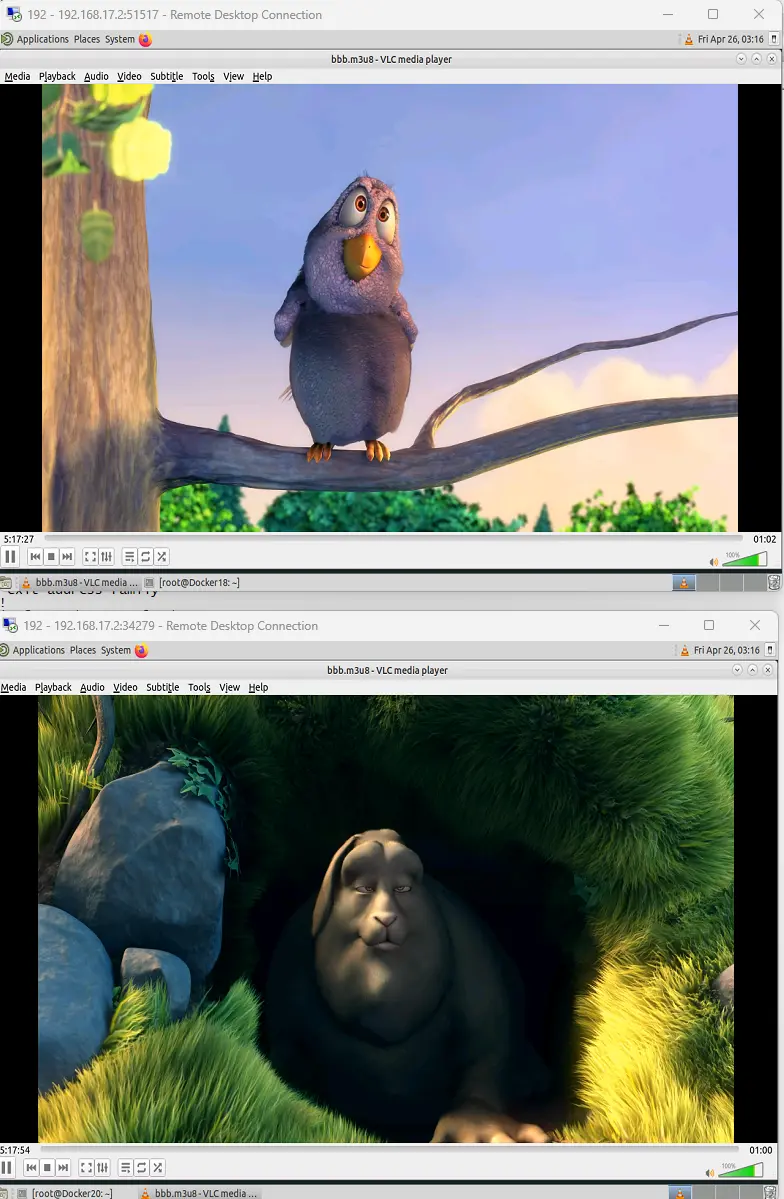
The stream is loading on both clients, they are not totally synced, but I do allow for segments to live in the cache for a couple of seconds, the hls-m3u8 contains a list of files (manifest) that it should be request in order, so depending on when a client joins and what files are listed in that manifest it will request the first file in the list.
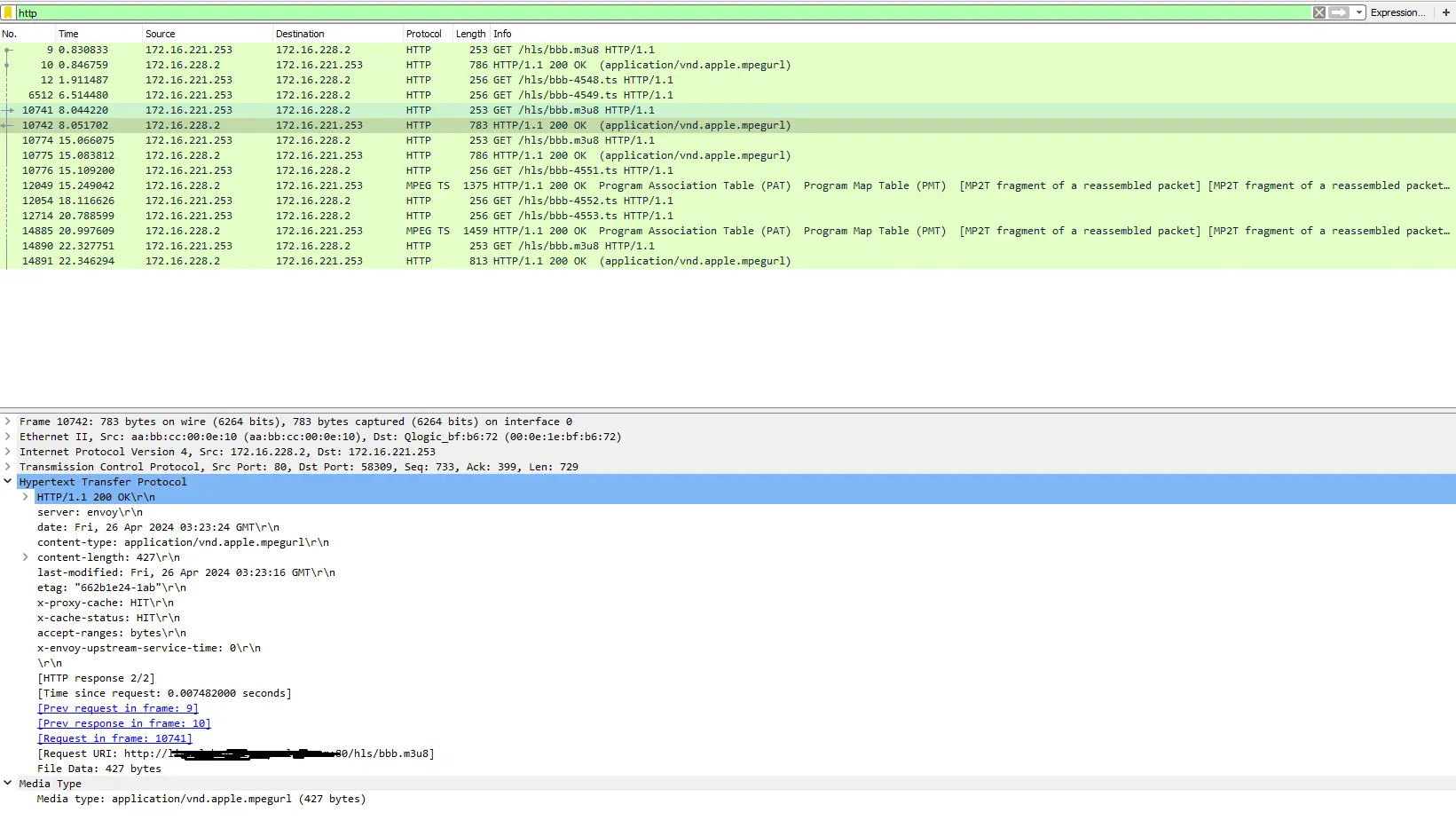
Lets take a look at a wireshark capture as well. In the capture you see that we have several HTTP requests, I have highlighted one of the 200 responses here.
- In the Hypertext Transfer Protocol can see that our x-proxy-cache and x-proxy-status headers are reported back that these are cache hits as well as the media type at the bottom which is currently HLS.
There is a high level look at how you might cache a live stream where you origin and your clients are separated by more than one network, and how to use NGINX as a proxy cache. The concept can be useful for more than just video.